vision transformers
read - https://arxiv.org/pdf/2010.11929
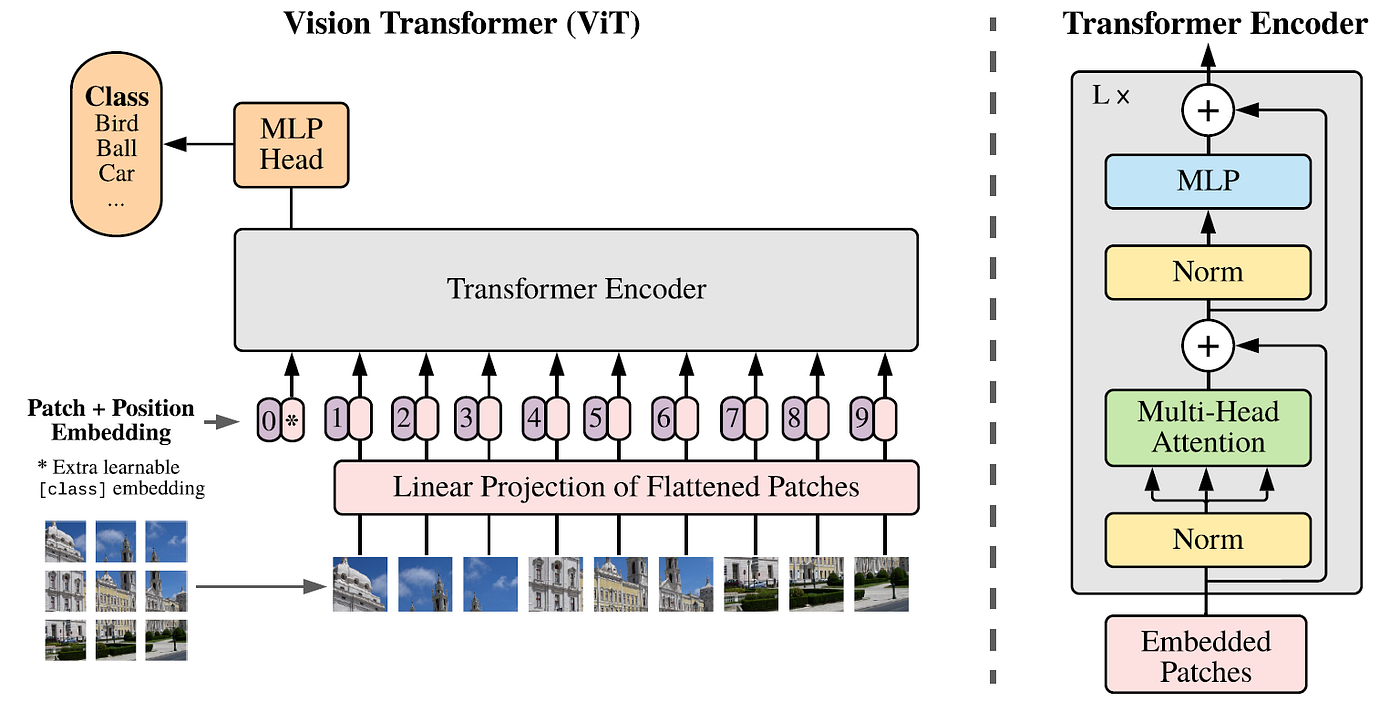
key differences from GPT architecture:
- an additional CLS token is added in the input sequence which helps in the final classification
- self attention in ViT happens without masking unlike GPT which uses Causal masked attention
- instead of having a vocab size to predict the next word, it has a list of labels to classify the image!
linear projection of flattened patches
- each image is broken into patches of 16 x 16 x 3 size which is flattened and linearly projected for the transformer!
- so each patch is converted to 768 dimensional token - (1 x 768) since 16 x 16 x 3 = 768
- to get the patch embedding we multiply the patch token with transpose of weight matrix of dim (1024 x 768) and add a bias term of dim (1 x 1024) to finally get a patch embedding of dim (1 x 1024)
- the final patch + positional embedding consists of number of (patches + 1) embeddings, this extra embedding is called class embedding which is actually used for classification in the end! without this the accuracy of the transformer in classification task is low!
- positional embedding - learnable params, part of the training just like the weight matrix to create the patch embeddings
architecture
- ViT uses an encoder only transformer so it uses non masked MHA, unlike GPT with masked MHA!
- it has L layers of encoder stacked and the skip connections helps in backward gradient flow during backprop avoiding vanishing and exploding gradients!
- it also uses layer norm to stabilize training making the mean of ip=0 and var=1
- finally after the transformer encoder blocks, only the CLS embedding is used by the MLP head to make the classification where it is converted into an output of n classes with softmax to decide the class with the highest probability!
coding the ViT
requirements:
- dataset - MNIST handwritten digits dataset
- preprocessing - loading dataset, and splitting into train + val and batches!
- MHA class
- Transformer encoder class
- Training loop
- Validation
code link - https://github.com/aniketpathak028/vision-transformer
Links:
202605242041