Deep Q-Learning
Frozen lake environment
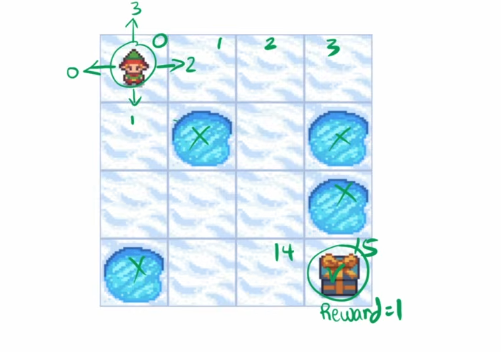
- 16 possible states numbered 0-15
- the agent can move up, down, left, or right
- on falling in cell with water the episode ends
- on reaching the end state ie. 15, the agent gets a reward of 1
- the agent can only be inside the grid
simple right? why not use a path finding algorithm instead of reinforcement learning??
why reinforcement learning?
because there is a flag called is_slippery = True which makes it tricky to solve the problem using simple path finding algorithm, so it is possible that the agent does not take the move that it is supposed to take based on some factor!
epsilon greedy algorithm
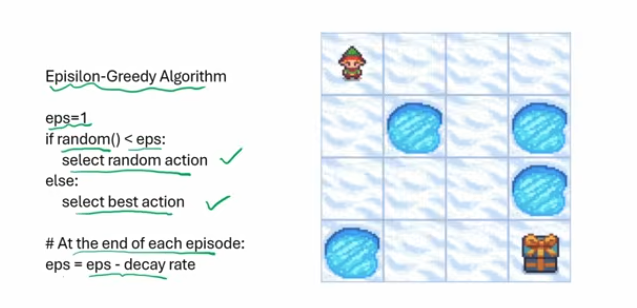
a classic algorithm for reinforcement learning where:
- we start with epsilon as 1 and generate a random number
- if the random number is greater we take the best action possible in that state
- else we select a random action
- at the end of each episode we decrease the epsilon by a decay rate!
Q Table vs Deep Q-Network
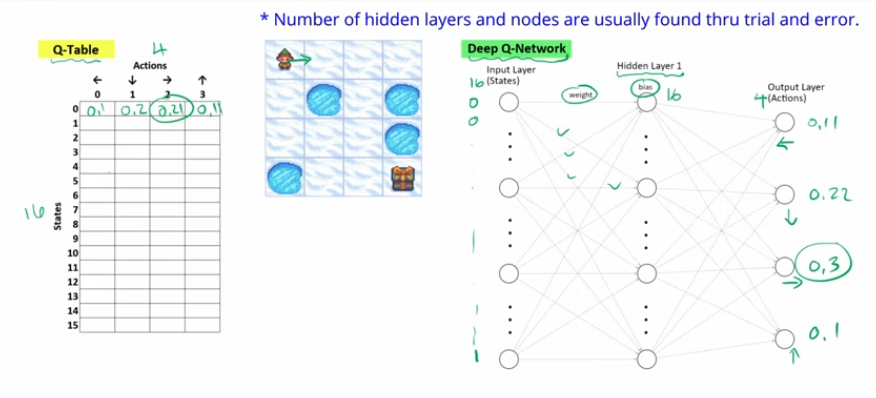
- a Q table is a permutation of all possible states and all possible actions in those states
- we choose the action for a specific state with the best highest q value or reward!
while
- a Q network is a neural network where we have n nodes in the input layer which is equal to the number of states and use one hot encoding to denote which state the agent current is in!
- the output of the network is the action with the highest q value!
- the number of hidden layers is a variable that can be tweaked using trial and error!
Links:
202605011716