swin transformer
paper link - https://arxiv.org/pdf/2103.14030
- shifted window transformer
- released by microsoft asia team
- proved that transformers could be used to solve any kind of vision problems - classification, segmentation or detection.
problems with ViT
- attention is costly as it take O(N^2) complexity to calculate attention which means it is directly proportional to the resolution of the image!
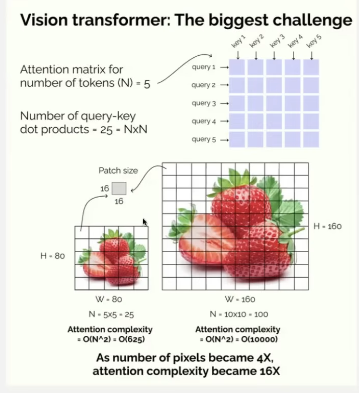
- the attention complexity increases with the resolution of the image which is a big concern!
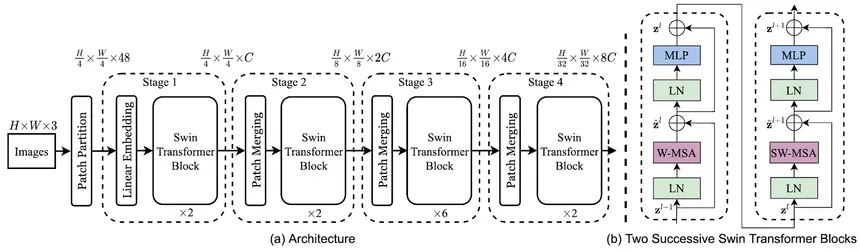
swin transformer architecture
works on the principle that attention need not be applied on the entire image instead could be calculated on smaller windows of patches!
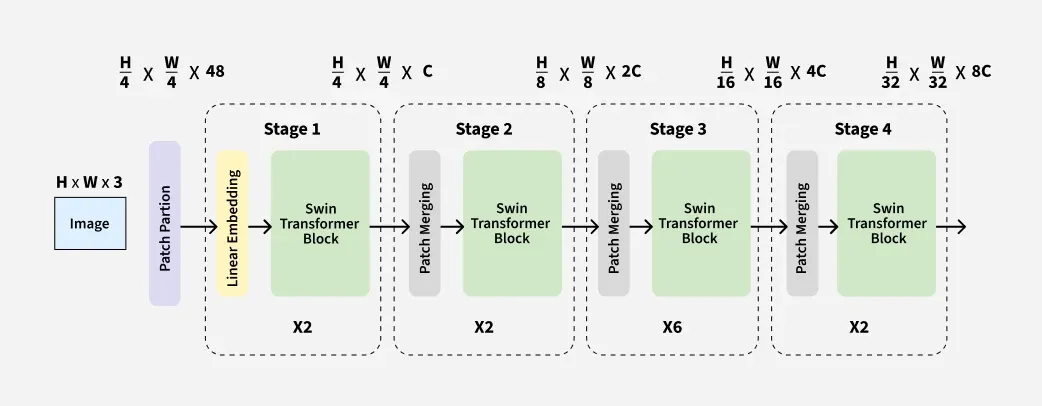
understanding the dimensions:
- Patch partition: input image → H x W x 3 → creating 4 x 4 patches across H and W → (H/4) x (W/4) x 48 (because there are 3 channels and 16 patches and each patch is 4 x 4 so the number of dimensions to represent each patch is = 4 x 4 x 3 = 48) so the final dim after patch partition is (H/4) x (W/4) x 48
- Linear embedding: in linear embedding we just scale the dimension to C (ie. the dimension which the transformer requires for this architecture) so we multiply our input with a matrix of 48 x C to transform it into our desired dimension ie. (H/4) x (W/4) x C (usually C=96 in swin)
- Patch merging: in patch merging we merge the patches to reduce the number of patches and increase the channel dimension! ideally we merge 2 patches along row and column so a patch of size 4 x 4 becomes 2 x 2 so our dimensions become (H/4) x (W/4) x C → (H/8) x (W/8) x 4C but we again multiply with 4C X 2C linear projection to change its dim to (H/8) x (W/8) x 2C
- the same thing keeps repeating again and again in further stages as patches get merged and channels get wider, the model gets a better context of rough and smooth edges in the image similar to CNNs
W-MSA:
- regular window cannot capture long term dependencies or attention which is tackled by shifted window
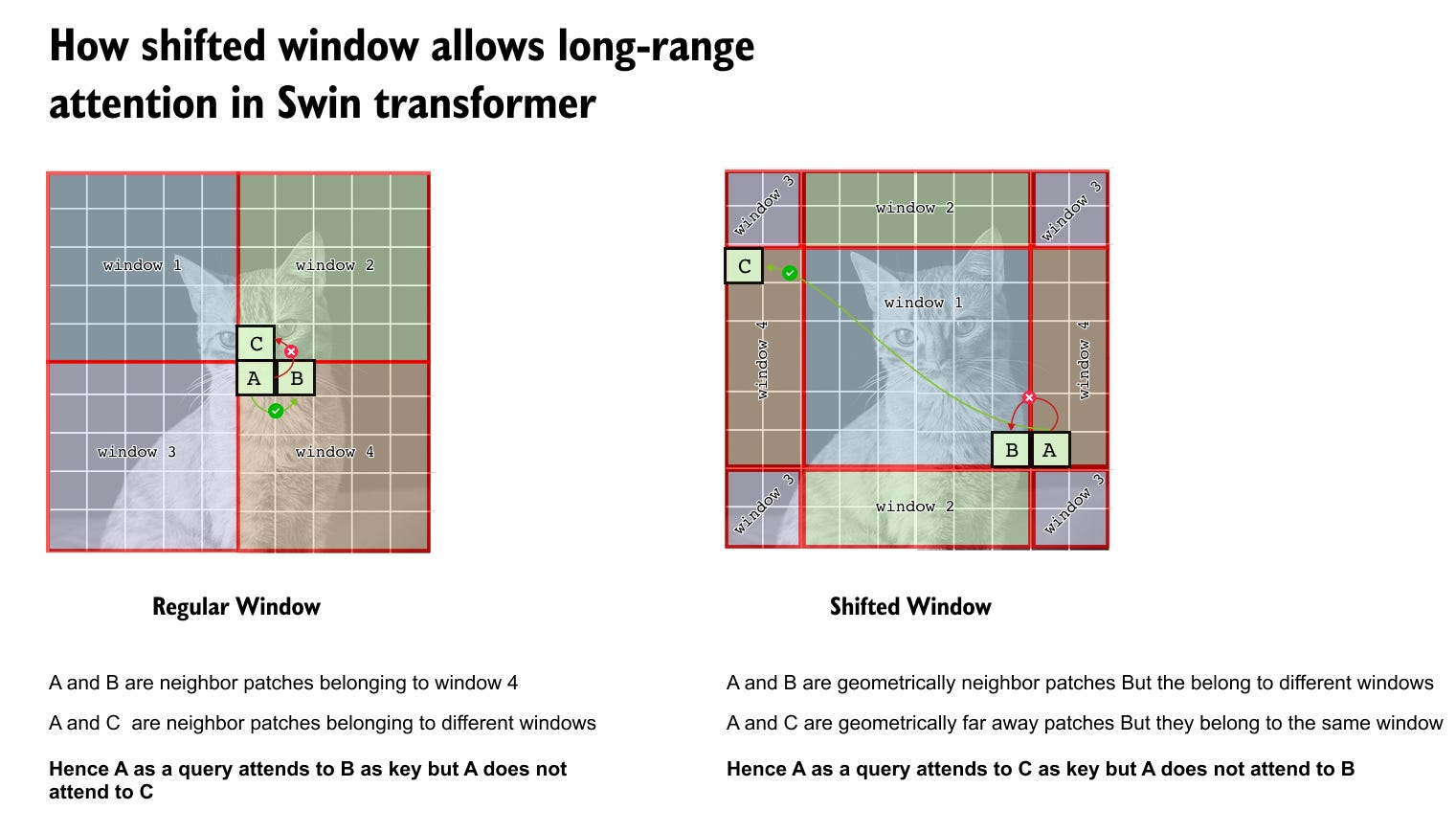
- each window is shifted my M/2 position in height and width which allows it to capture the attention between patches far apart!
- in swin transformer regular block when calculating the attention scores, we add a bias term called positional bias

Shifted-Window:
- however in shifted window we cannot calculate the attention this way as the window keeps moving so we use a mask_ij to calculate which patches are in the current window by masking the other patches as -infinity and we also add a relative positional bias
- to think of it if a window contains 7 x 7 patches, the number of Q, K attention pairs would be 49x49=2401 for each attention pair, calculating a positional bias would be challenging, so swin uses relative positioning
- the positional bias here unlike in ViT is calculated during calculating attention score!

why we do not need 2401 bias terms?
- if we consider rel positions of any two patches in a 7x7 window, it would range:
- delta y = -6 to 6 (ie. any 2 patches in the window could be min -6 dist apart or max 6 )
- delta x = -6 to 6
- which makes the number of possibilities as 13 x 13 = 169
- for each of these possibilities the model learns the appropriate weight during training!
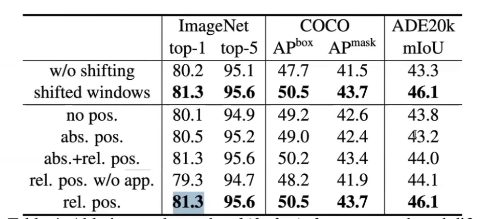
architecture
Let’s take a batch of 2 images - [2, 3, 28, 28] (this means that there are 2 images of 28x28 with 3 channels):
- we have to make patches in these images, let’s say we create patches of 2x2 since the res of the image is less we get -
nn.Conv2d(3, 48, 2, 2)- [2, 48, 14, 14] - now we have to flatten this image from 14 x 14 to 196 patches each having 48 dim so we get the flattened vector as - [2, 196, 48] - dim 1 and 2 was transposed to make it fit the transformer input so
x= x.flatten(2).transpose(1,2) - next in patch partition we just convert this vector from 48 dim to C dim
Links:
202605261605