UNet

- the word semantic means it does not matter an image of an apple, text - “apple”, or your mind thinking apple, it means the same!
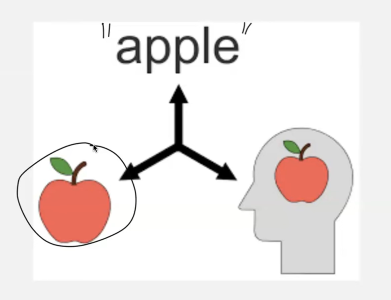


- UNet performs semantic segmentation
What is UNet architecture?
-
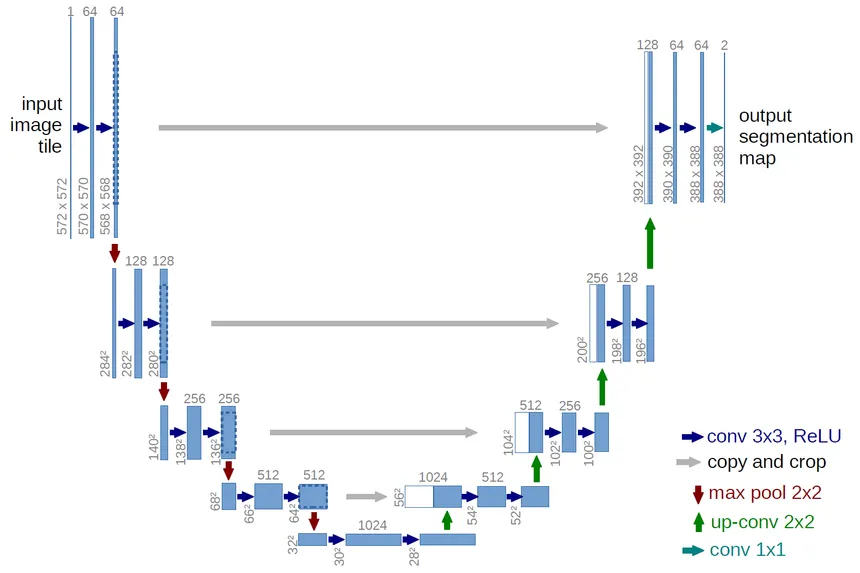
the UNet architecture has a U shaped transformation where the left part is called the encoder, the bottom is called the bottleneck and the right part is the decoder
-
the unique part in UNet is that is uses skip connections between the respective layers in encoder and decoder to better train the network and preserve the original image characteristics which helps the gradients flow better during backprop!
-
input image is of dim - 572 x 572 x 1 (gray scale image)
-
3 x 3 x 1 filter convolution with 64 filters result in 570 x 570 x 64 output dim
-
another convolution by 3 x 3 x 64 result in 568 x 568 x 64 output dim
-
after block 1 when it goes to block 2, it goes through a max pooling layer of 2 thus it loses half of its width and height - 284 x 284 x 64
-
then it goes through another 3 x 3 x 64 filter conv of 128 filters reaching dim 282 x 282 x 128 and so on..
-
finally it reaches the bottleneck where it has the dim of 32 x 32 x 512 and there are 3 consecutive convolutions to have the final output of 28 x 28 x 1024 and then it gets up-convoluted using bilinear interpolation to have an output of 56 x 56 x 1024
-
there is also a copy and crop operation that takes place and concatenates the encoder outputs after cropping its input dim to match the decoder input dimension and directly concatenates it along the channel dim!
-
concatenation makes sure that the image has both the abstract representation coming from the bottleneck and the original representations from the encoder!
-
so in summary we are compressing the image and then decompressing it to get back the actual image! in the process we definitely lose a lot of information like the dimension of the original image is no longer preserved if you observe we started from 572 x 572 x 1 and at the end we finally have an image of size 388 x 388 x 2
-
the final channel dim 2 represents the 2 image masks for the class and the background in the image!
parts of unet:
- encoder - compresses the image into an abstract representation by convolution and max pooling
- bottleneck - loss of representation is prevented because there are multiple channels
- decoder - scales back the image into its original dim
unet loss
loss = (loss due to pixel mismatch + loss due to object alignment) / 2
- just looking at how many pixels were predicted correctly will not work
- we must also look at false positive and true positive object detections
Links:
202606031256