CLIP by OpenAI
paper - https://cdn.openai.com/papers/Learning_Transferable_Visual_Models_From_Natural_Language.pdf
video - https://www.youtube.com/watch?v=fQyHEXZB-nM
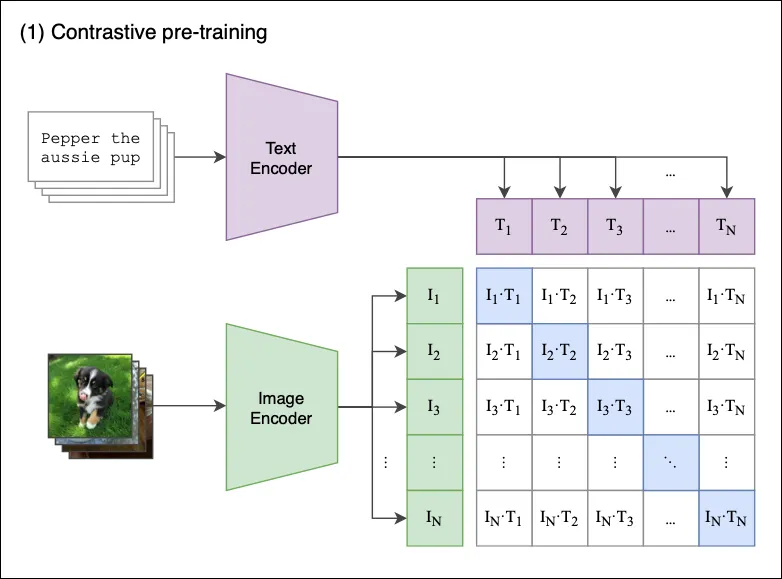
- the goal of the paper : “demonstrating that a simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 Million (image, text) pairs collected from the internet”
Links:
202605282142