DETR - Detection Transformer
- object detection - localization, classification, confidence
- obj detection models - DETR, YOLO, FasterRCNN etc.
- idea: given ip img, the model tries to predict a bounding box
- DETR eliminates anchor boxes and the need for Non Maximum Supression (NMS)
- DETR uses direct set prediction!
a naive object detection model
- to determine a rectangle uniquely in an img, we need its - height, width and centroid coordinates (x, y)
- ground truth = [1, 0, 1, 0.5, 0.5, 0.65, 0.65] which are - prob of dog, prob of cat, confidence, bounding box centroid x, y, height, width
- this naive model has issues like - multiple objects in the same image, multiple number of same classes in the same image etc.
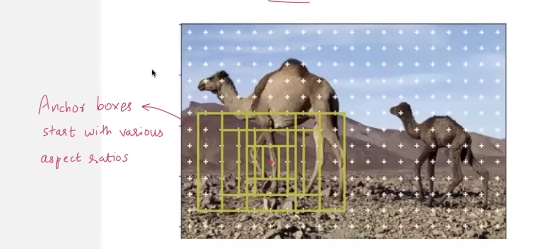
Anchor boxes
- predefined bounding box shapes that help an object detection model guess the size and location of objects in an image
- instead of predicting boxes from scratch, the model starts from these fixed “anchor” shapes and adjusts them.
- these anchor box features were hand engineered by humans like - aspect ratios, height, width, etc.
Non maximal supression
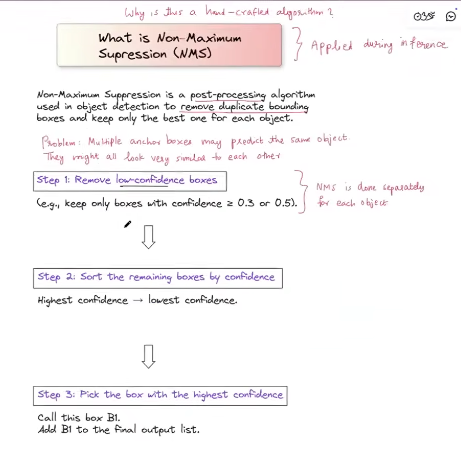
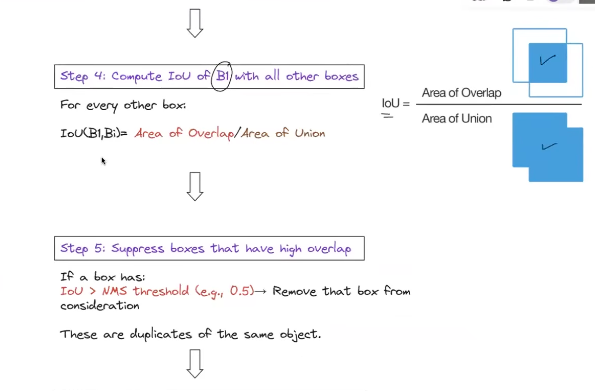

- NMS is hand crafted
- NMS relied heavily on a fixed IoU threshold, which can remove good boxes or keep bad ones if the threshold is poorly chosen.
set prediction
- DETR always predicts a fixed number of bounding boxes eg. it predicts 100 bounding boxes, but there is only 1 image in the entire image, it will still have 100 bounding box preds with only 1 pred having the obj inside it!
- why?
- traditional deep networks cannot natively predict a variable number of outputs
- a neural net normally produces a fixed size output vector - 1000 classes in ImageNet
- but in obj detection, we require:
- a variable number of objects
- arbitrary positions
- with arbitrary shapes

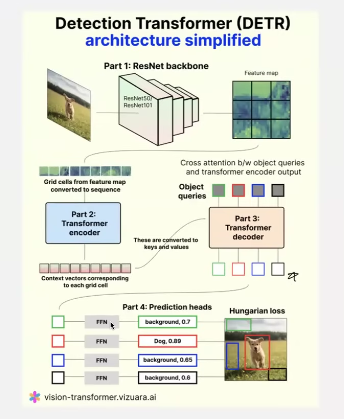
architecture
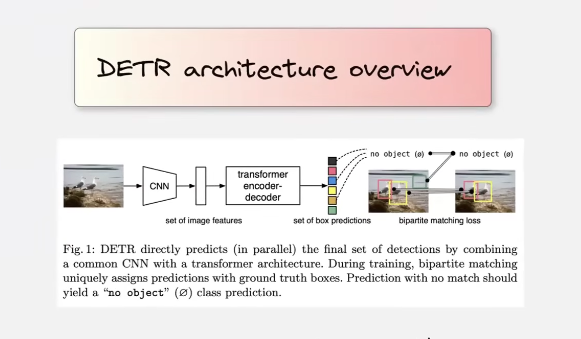
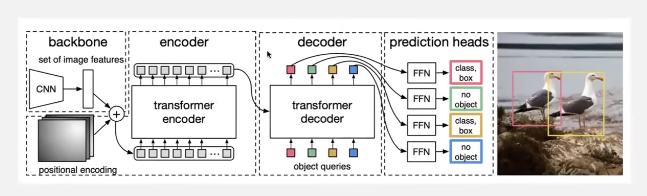
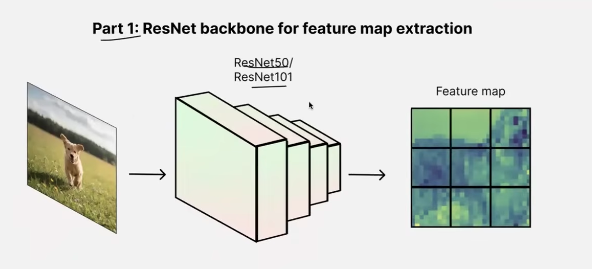
- feature maps are multi channeled with much lower resolution than the original image
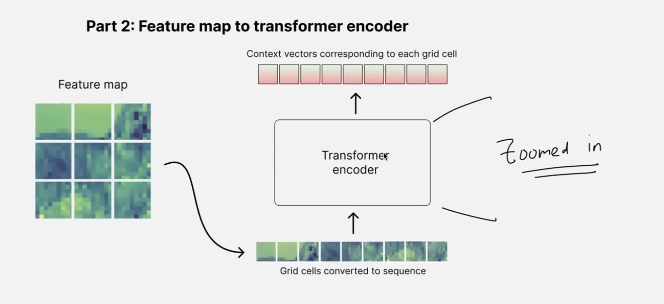
- the feature map is flattened before passing to the transformer encoder
- the feature map is of dim - h x w x d where d is the dim needed by the transformer
- usually these tokens are not equivalent to patches because these are low resolution and do not need to be divided into further patches like high res images!
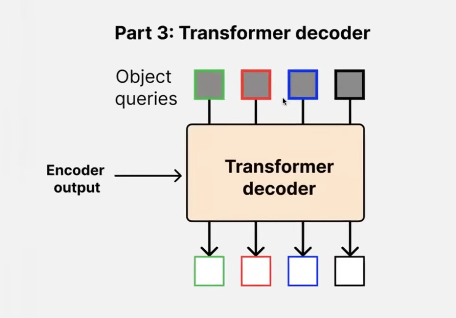
number of boxes with obj + no-object = object queries for ex here it is 4! These object queries which are of dim “d” as of transformers get transformed into bounding boxes by the decoder in combination with the encoder output above!
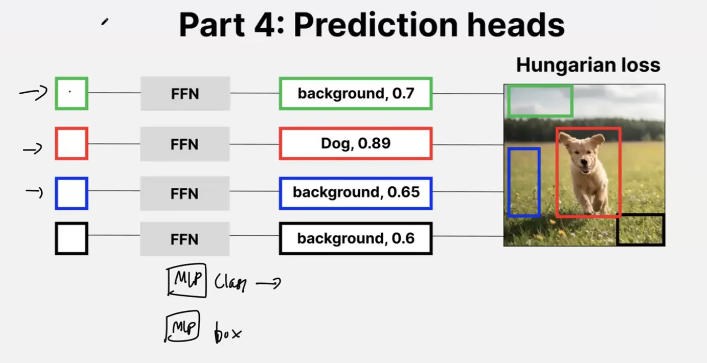
complete architecture
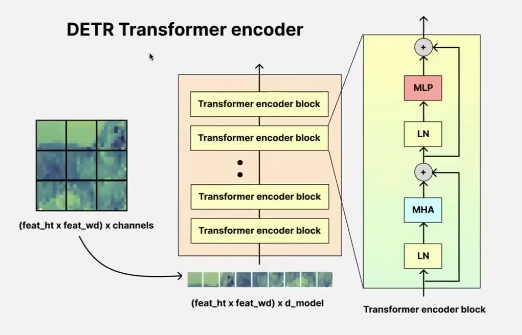
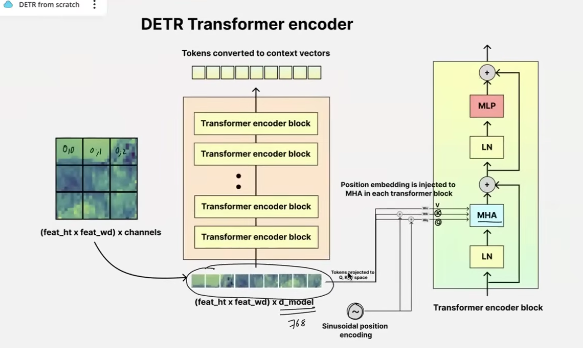
encoder
positional embedding
few key points to note is that:
- pos embeddings for encoder are added before each MHA block in each transformer block instead of just once when the tokens are created
- sinosoidal pos encoding (which is not a learnable pos encoding instead a fixed one) is used for both K and Q:
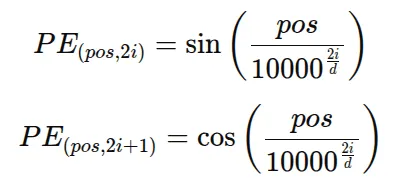
decoder
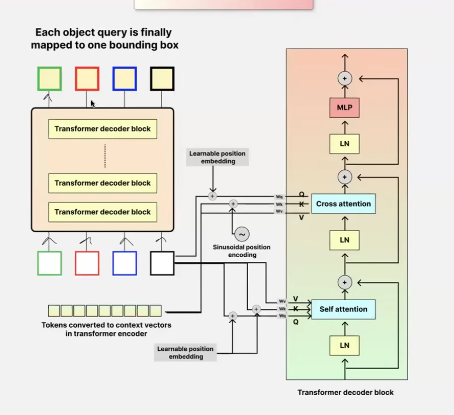
- the tokens converted to context vectors in encoder are used for cross attention in decoder block as Keys and Values!
- the object queries (which symbolize the number of objects to be detected are random learnable vectors) are used as Queries in cross attention!
- first the object queries are passed thro decoder block where they get layer normalized and a self attention, in this case the pos embedding is learnable instead!
- later these enriched obj query embeddings are used for cross attention with the output from encoder!
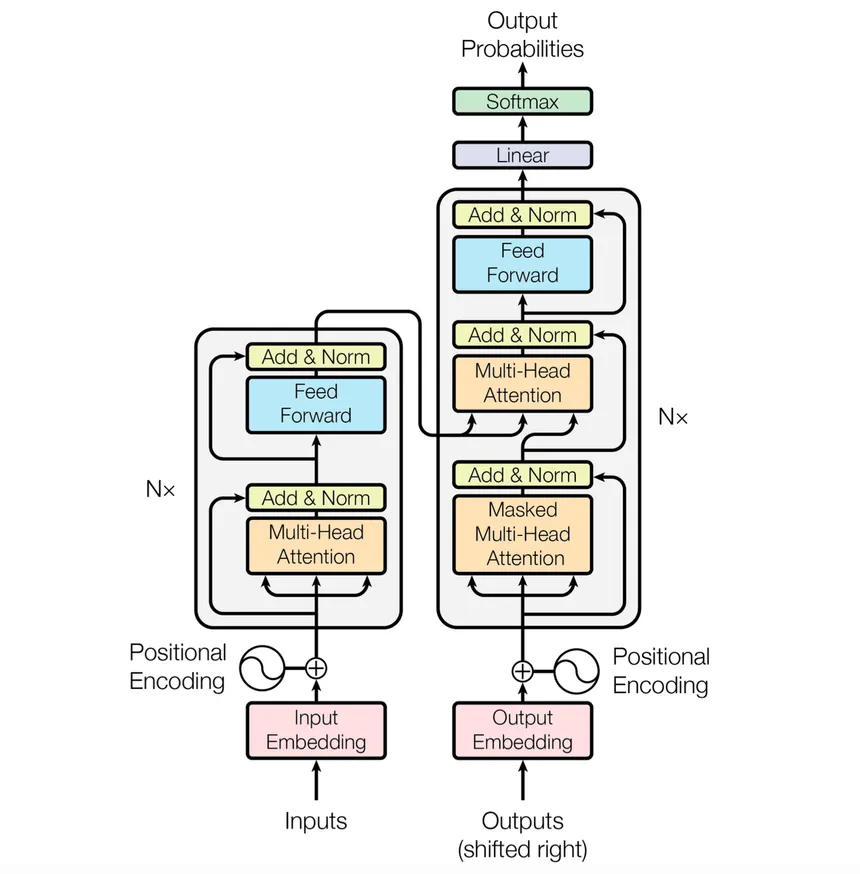
compare this architecture with the original paper - attention is all you need
- DETR loss is a matching problem as it does a set number of predictions
- these predictions may have some Ground truth object or be null
- then these predictions are matched to the original ground truth consisting of the actual object and null
- instead of using NMS, because DETR predicts an object only once, it uses something known as Hungarian Loss!
Hungarian Loss
- used when we try to map a set to another set of objects!
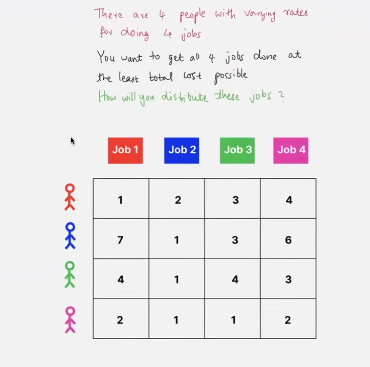
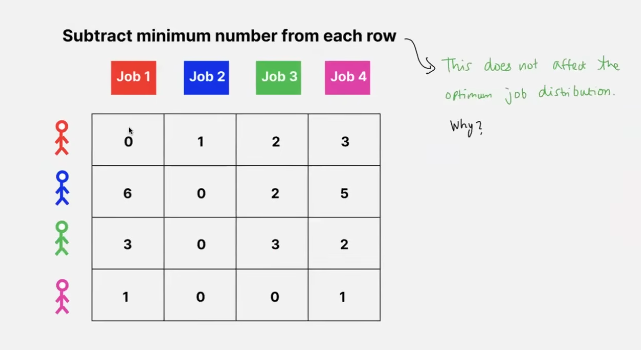
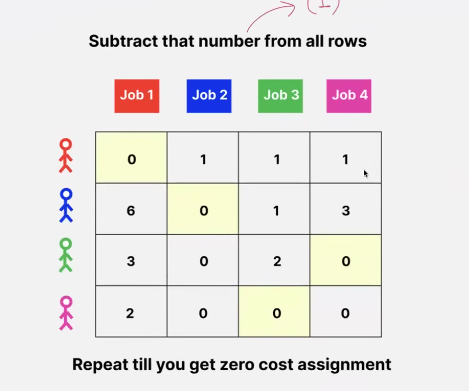
- because substracting the same number doesn’t change the distribution in a row!
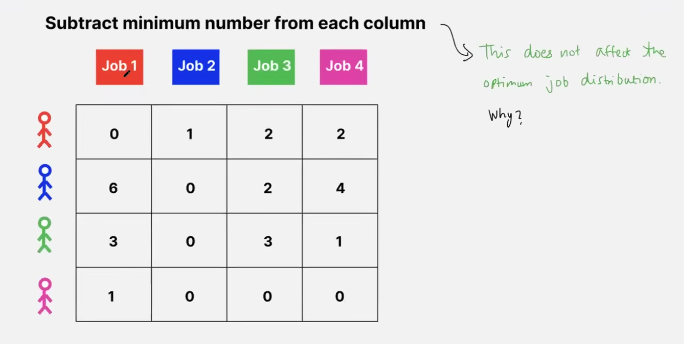
- same logic can be applied across columns too!
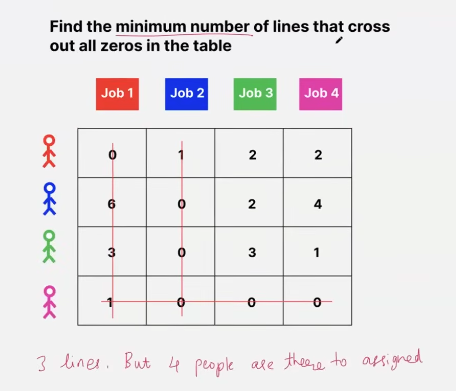
- look at the numbers that are not crossed and find the min! here - 1
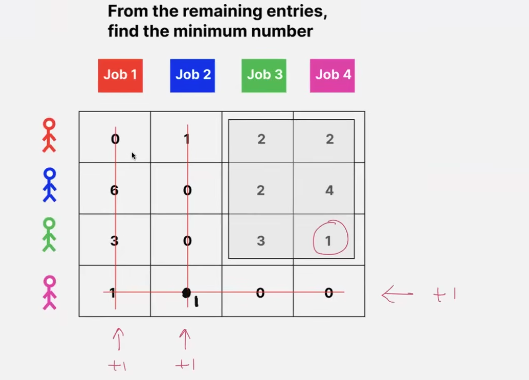
-
now add this min number to all the crossed entried and substract it back from the entire matrix!
-
this is now the zero cost assignment and the actual cost is the sum of the cost for each job in the original matrix = 6
why hungarian loss?
- because the DETR matching problem is similar we have a bunch of preds which we need to map with the GT!
- in DETR ideally there are about 100 object queries and hence 100 preds!
- usually when there are multiple object queries and multiple ground truths, can we use hungarian matching!



- in DETR we use hungarian matching between the predicted bounding boxes by the model and the ground truth.c
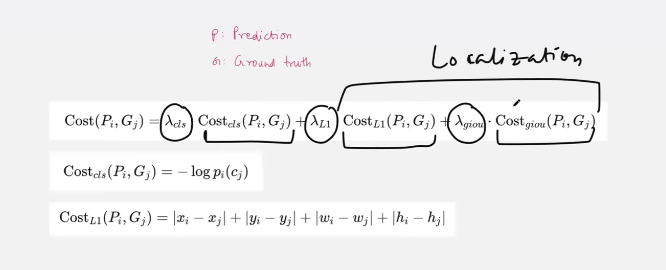
DETR loss
- classification loss: penalizes the model for incorrect classification of the bounding box
- localization loss
- L1 loss: absolute diff of x, y, w, h with predicted x’, y’, w’, h’
- GIOU loss: hungarian matching loss

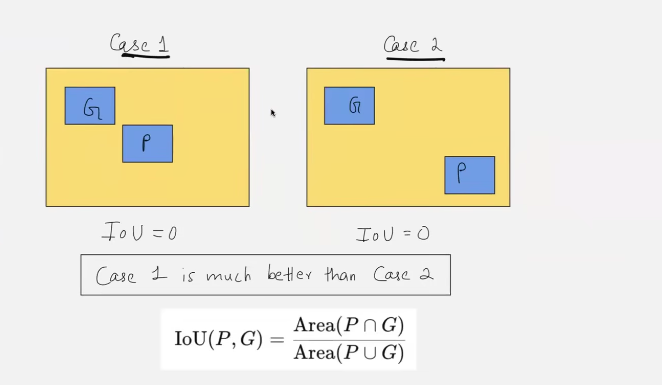

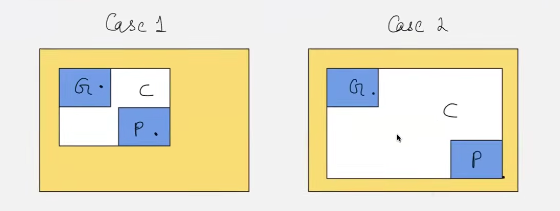

- hence greater GIOU is better! as GIOU(1) > GIOU(2)
Links:
202605301813