Building a simple deep nn with 2 hidden layers
notes - https://miro.com/app/board/uXjVIPXuHKk=/?share_link_id=843762054496 colab - https://colab.research.google.com/drive/1m4JuGfPdqL59SF1X_6lcRT-NEKy4azov?usp=sharing
problems with the linear layer in the last experiment
- we had a single layer which means we just converted the image (H x W x C) into patches by flattening and used it to predict the class!
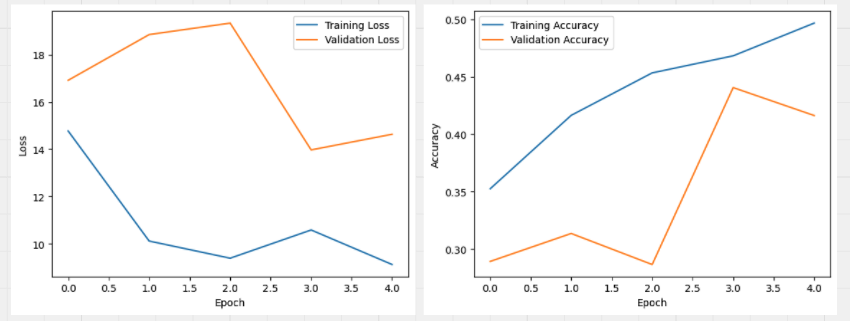
- as per the training and validation curves, the model was clearly trying to overfit after a certain number of epochs as the training acc increases and the validation accuracy plateaus and decreases
- the batch size (16), optimizer setting (0.001) - i.e. hyperparam tuning could have been better but this can be done only with trial and error!
new model architecture
old model params: - hidden layer 1 : 224 x 224 x 3 = 150528 - output layer : 5 - number of params : 150528 x 5 = 752640 (trainable params) new model params: - HL 1 : 224 x 224 x 3 = 150528 - HL 2 : 128, activation: RELU - output layer: 5 - number of params : 150528 x 128 + 128 x 5
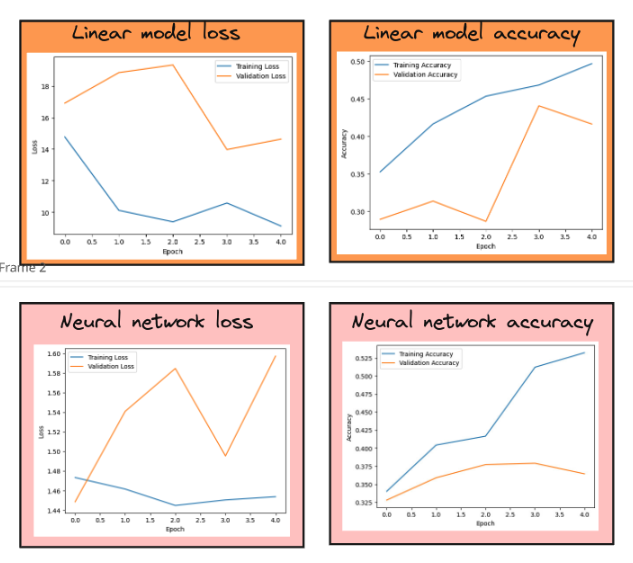
results of the new model
- unlike expected, that the accuracy would increase, it remains almost the same
- while the loss in now lower! this means the model is predicting the class more confidently however the accuracy remains the same because of the other hyperparams like - batch size, LR, image size, EPOCHs etc. and also because it is ultimately a simple nn with only 2 layers!
Hyperparams vs params:
- params - weights, biases
- hyperparams - batch size, LR, loss func, # hidden layers, epochs, image size
- image size - reducing size can help the model run faster but it loses information that could be useful for the classification task! ex- 224 x 224 → 64 x 64
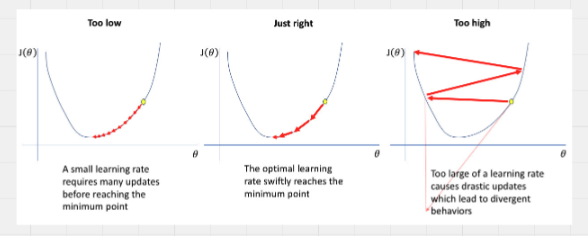
- Batch size
- About ADAM

comparison
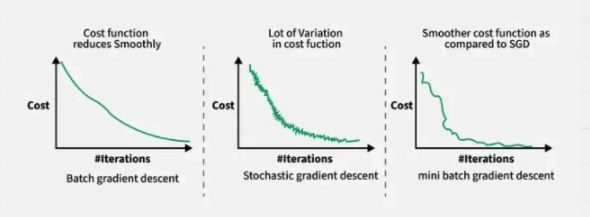
- Batch GD - weight is updated once after one epoch (which is the entire Dataset) the model calculates the loss for all images in the dataset and then updates the weights based on an avg of the loss!
- Stochastic GD - weight is updated (# of images) times in one epoch as the model updates the weights after calculating the loss for a single image itself
- Mini batch GD - weight is updated after a batch of image predictions are made (say batch of 12 images) so if there are 240 images in a Dataset, the weight would be updated 20 times in one epoch ie. after each batch!
- ADAM - similar to mini batch in terms of weight update step but uses advanced update strategies
random experiments
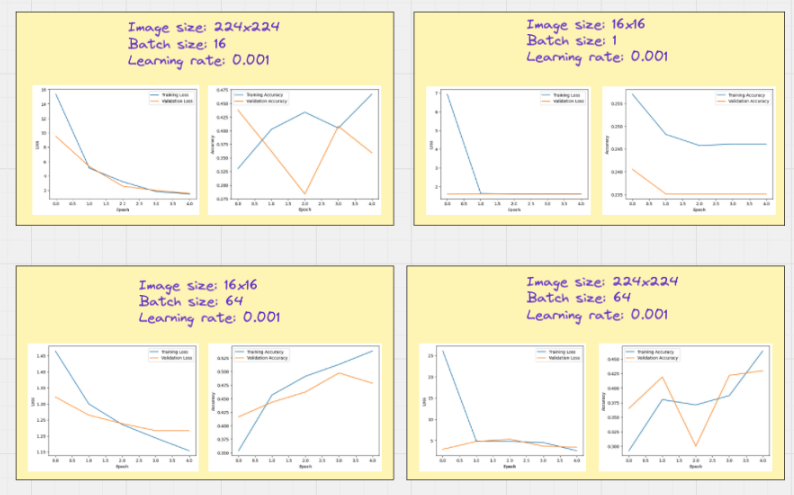
- a larger batch size results in a smoother graph without much steep changes!
Links:
202606091019